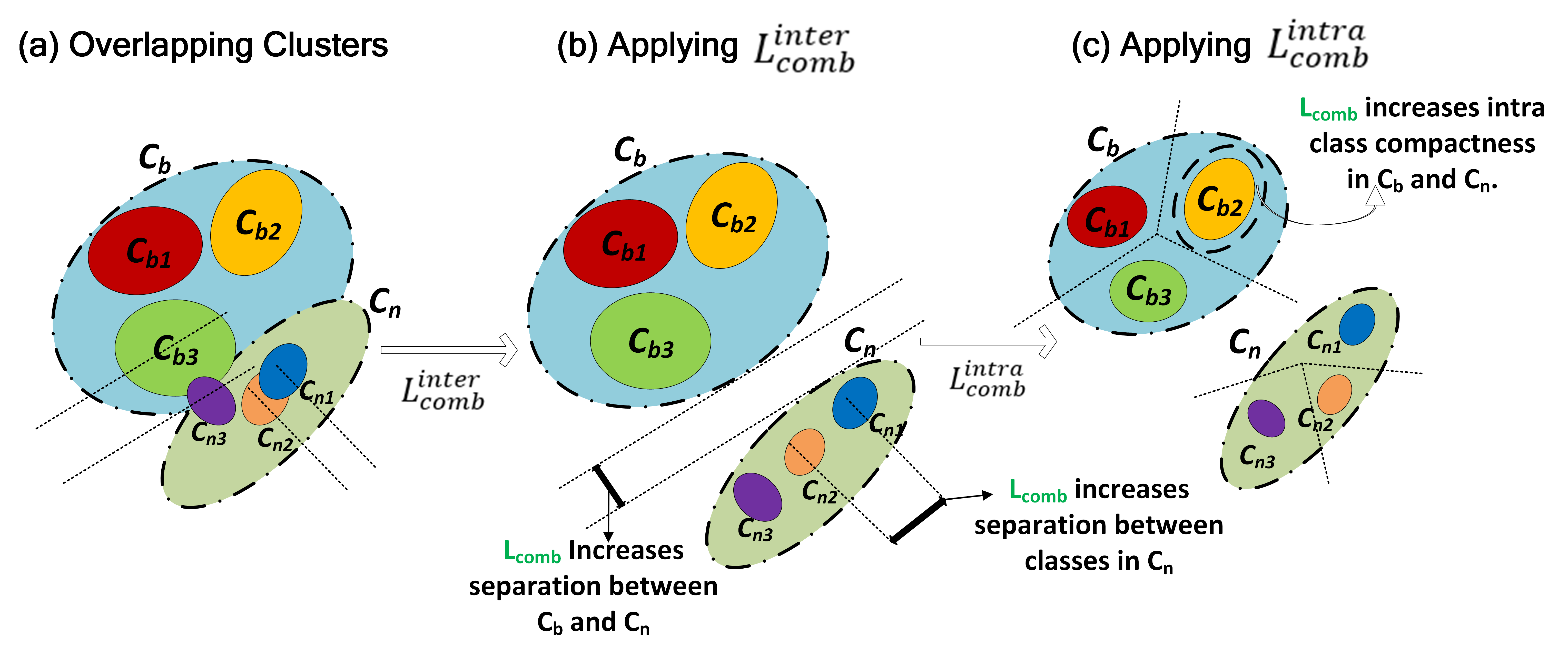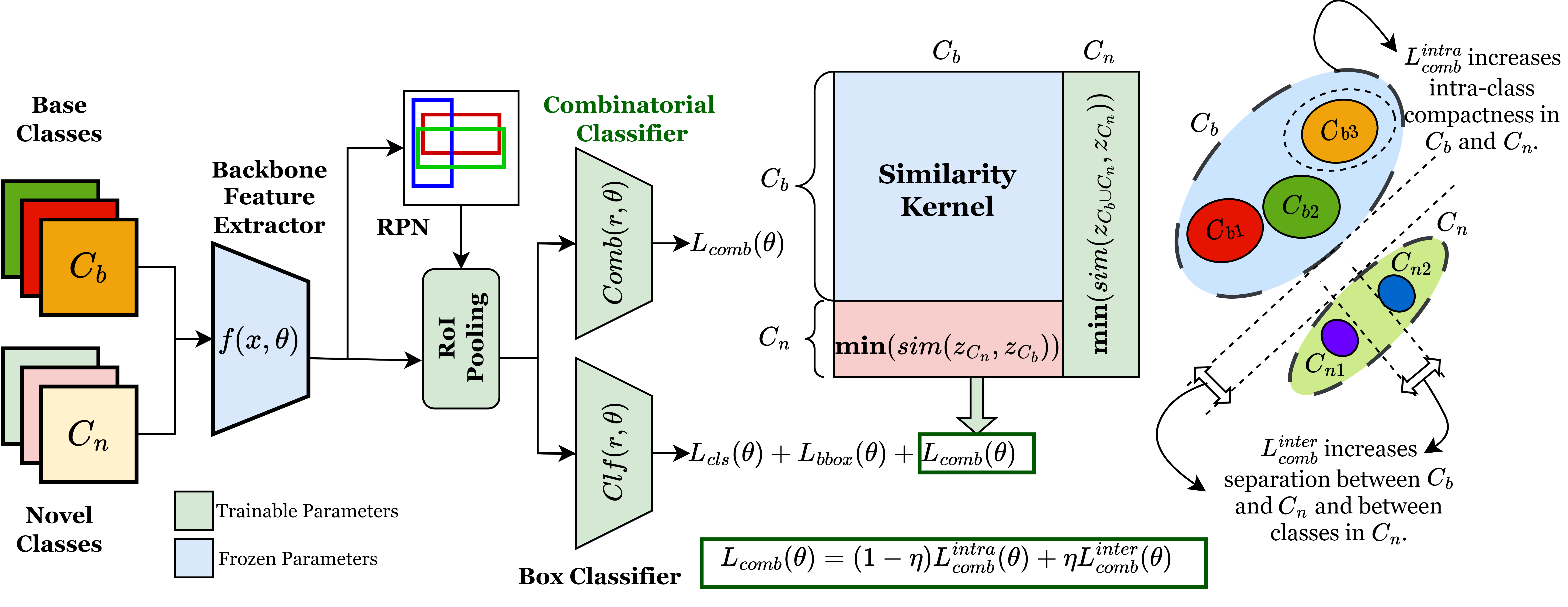
SMILe introduces a family of Submodular combinatorial objectives based on Submodular Mutual Information designed to tackle the challenge of Class Confusion and Catastrophic Forgetting in Few-Shot Object Detection (FSOD) tasks.
Abstract
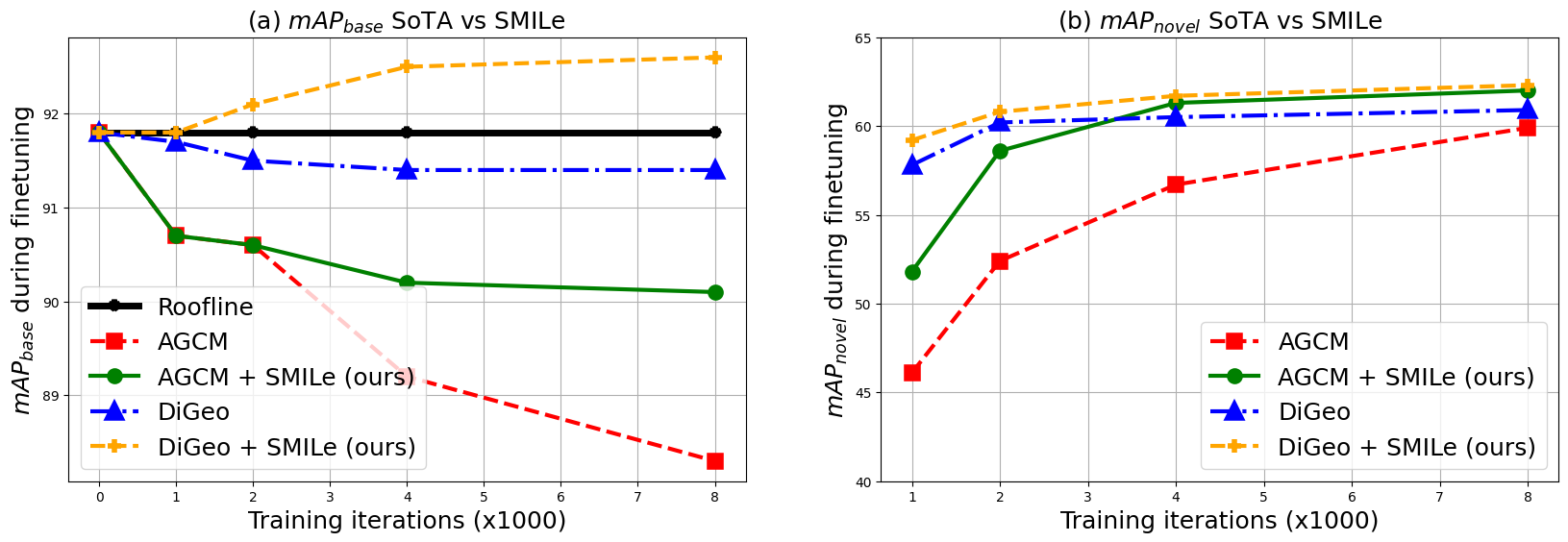
Confusion and forgetting of object classes have been challenges of prime interest in Few-Shot Object Detection (FSOD). To overcome these pitfalls in metric learning based FSOD techniques, we introduce a novel Submodular Mutual Information Learning (SMILe) framework for loss functions which adopts combinatorial mutual information functions as learning objectives to enforce learning of well-separated feature clusters between the base and novel classes. Additionally, the joint objective in SMILE minimizes the total submodular information contained in a class leading to discriminative feature clusters. The combined effect of this joint objective demonstrates significant improvements in class confusion and forgetting in FSOD. Further, we show that SMILe generalizes to several existing approaches in FSOD, improving their performance, agnostic of the backbone architecture. Experiments on popular FSOD benchmarks, PASCAL-VOC and MS-COCO, show that our approach generalizes to State-of-the-Art (SoTA) approaches improving their novel class performance by up to 5.7% (3.3 mAP points) and 5.4% (2.6 mAP points) on the 10-shot setting of VOC (split 3) and 30-shot setting of COCO datasets respectively. Our experiments also demonstrate better retention of base class performance and up to 2× faster convergence over existing approaches, agnostic of the underlying architecture.
The SMILe Framework
SMILe introduces a paradigm shift in FSOD by imbibing a combinatorial viewpoint, where the base dataset,
\(𝐷_{𝑏𝑎𝑠𝑒}= \{ 𝐴_1^𝑏, 𝐴_2^𝑏, …, 𝐴_{|𝐶_𝑏|}^𝑏\}\), containing abundant training examples from \(𝐶_𝑏\) base classes
and the novel dataset, \(𝐷_{𝑛𝑜𝑣𝑒𝑙}=\{𝐴_1^𝑛, 𝐴_2^𝑛, …, 𝐴_{|𝐶_𝑛|}^𝑛\}\) containing only K-shot (\(𝐴_𝑖^𝑛 = 𝐾\)
for \(𝑖 \in [1, 𝐶_𝑛]\)) training examples from \(𝐶_𝑛\) novel classes.
The striking natural imbalance between number of samples in the base and the novel classes leads to confusion between
existing (base) and newly added (novel) few-shot classes. We trace the root cause for class confusion to large inter-class
bias between base and novel (K-shot) classes. This results in mis-classification of one or more base classes as novel ones.
Further, in a quest to learn the novel classes \(C_n\) the model seldom forgets feature representations corresponding to
the previously learnt base classes. Even though several techniques in FSOD adopt a replay technique (provide K-shot examples
of the base classes during few-shot adaptation) the lack of discriminative features results in catastrophic forgetting of
the base classes.