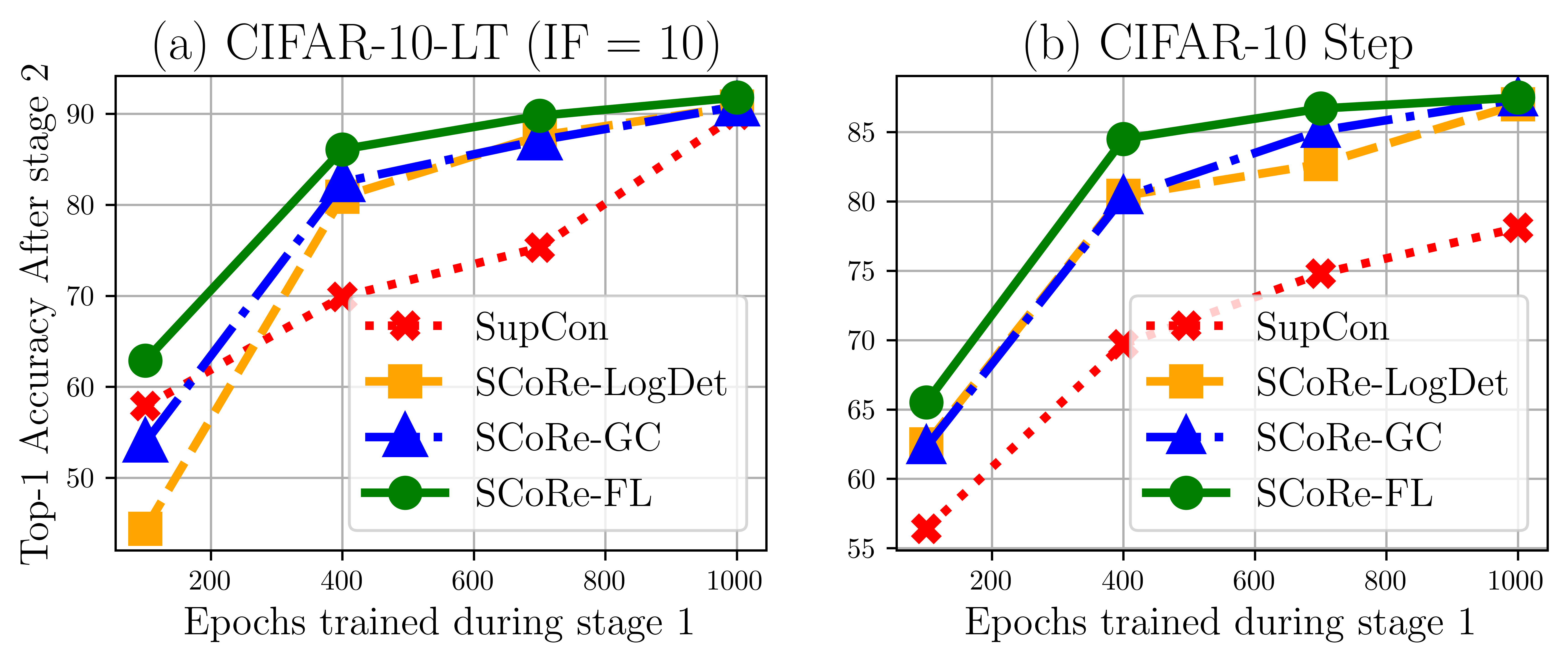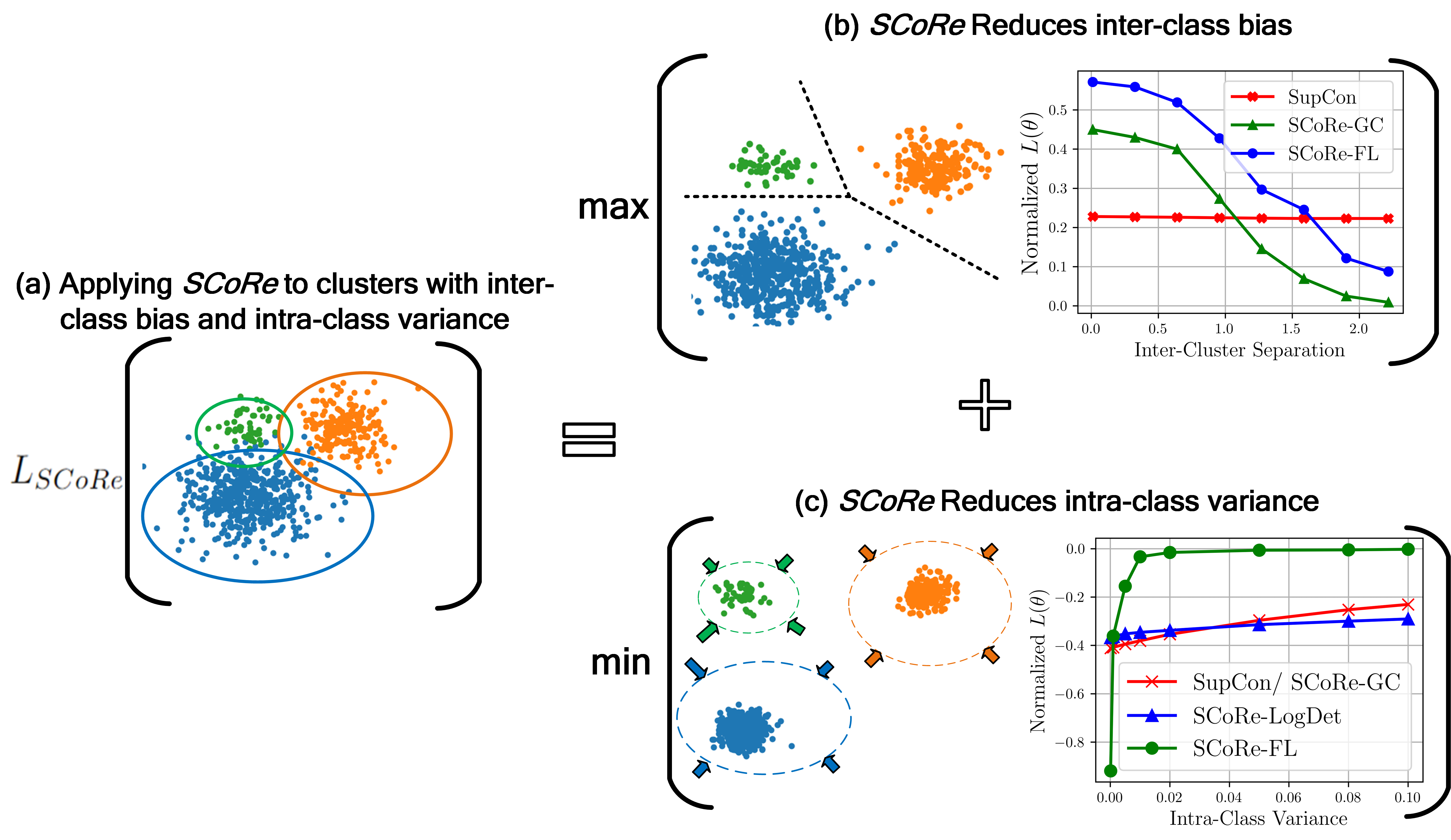
SCoRe introduces a family of Submodular combinatorial objectives designed to tackle the challenge of inter-class bias (b) and intra-class variance (c) demonstrated in Long-tail recognition tasks.
Abstract
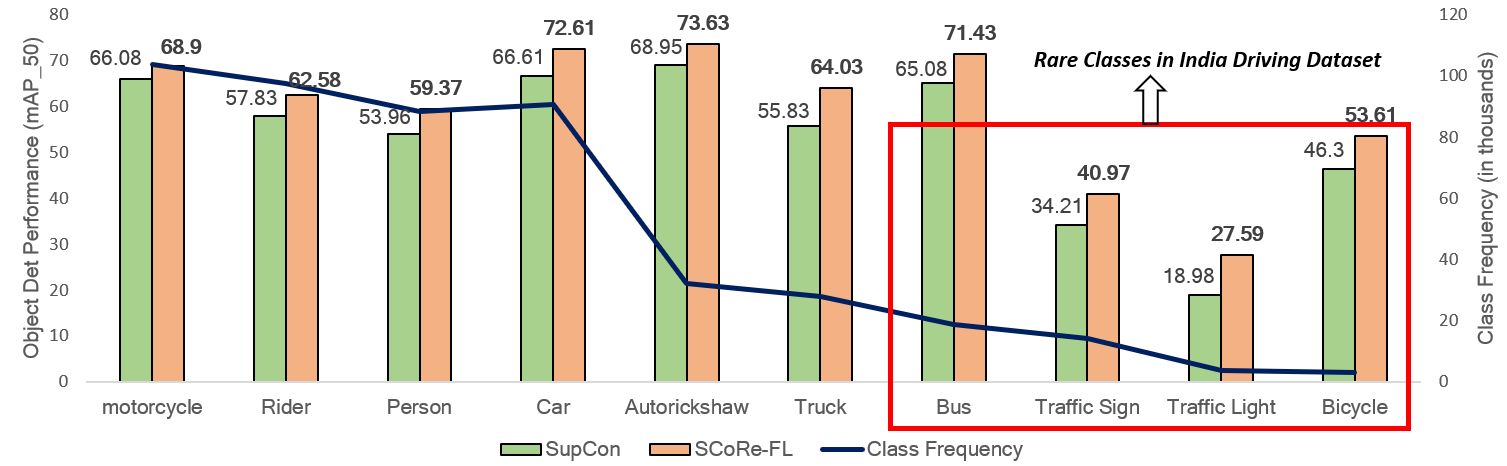
In this paper we introduce the SCoRe (Submodular Combinatorial Representation Learning) framework, a novel approach in machine vision representation learning that addresses inter-class bias and intra-class variance. SCoRe provides a new combinatorial viewpoint to representation learning, by introducing a family of loss functions based on set-based submodular information measures. We craft two novel combinatorial formulations for loss functions, that model Total Information and Total Correlation, that naturally minimize intra-class variance and inter-class bias. Several commonly used metric/contrastive learning loss functions like supervised contrastive loss, orthagonal projection loss, and N-pairs loss, are all instances of SCoRe, thereby underlining the versatility and applicability of SCoRe in a broad spectrum of learning scenarios. Novel objectives in SCoRe naturally model class-imbalance with up to 7.6% improvement in classification on CIFAR-10-LT, CIFAR-100-LT, MedMNIST, 2.1% on ImageNet-LT, and 19.4% in object detection on IDD and LVIS (v1.0), demonstrating its effectiveness over existing approaches.
Inter-Class Bias and Intra-Class variance in Long-tail Recognition
Long-tail recognition encompasses both imbalanced and few-shot classification tasks in the presence of both
abundant (head) and rare (tail) classes in the data distribution. This introduces a natural bias towards
the abundant classes and large variance within each abundant class in models trained on such distributions.
Representation learning in this space requires a model to learn discriminative features not only from the
abundant classes but also from the rare ones. Unfortunately, models trained on real-world datasets
demonstrate two main challenges - inter-class bias and intra-class variance resulting in
overlapping clusters alongside large cluster variance.
Inter-Class bias manifests itself as mis-predictions in rare classes being predicted as one or more of the
visually similar abundant classes. This mis-prediction results from the bias existng in the trained model, towards
the abundant classes demostrating cluster overlaps between head and tail classes in the embedding space as shown in
the figure below.
Figure 1: Resilience to inter-class variance by objectives in SCoRe. SCoRe objectives like SCoRe-FL show a large variation to intra-class variance over SoTA approaches like SupCon.
Intra-Class Variance manifests itself as the large variance within each class (see below figure) resulting in cluster overlaps between abundannt and rare classes. It also manifests itself as creation of local sub-centers intensifying the bias of the underlying model towards the head classes resulting in poor performance on the tail classes.