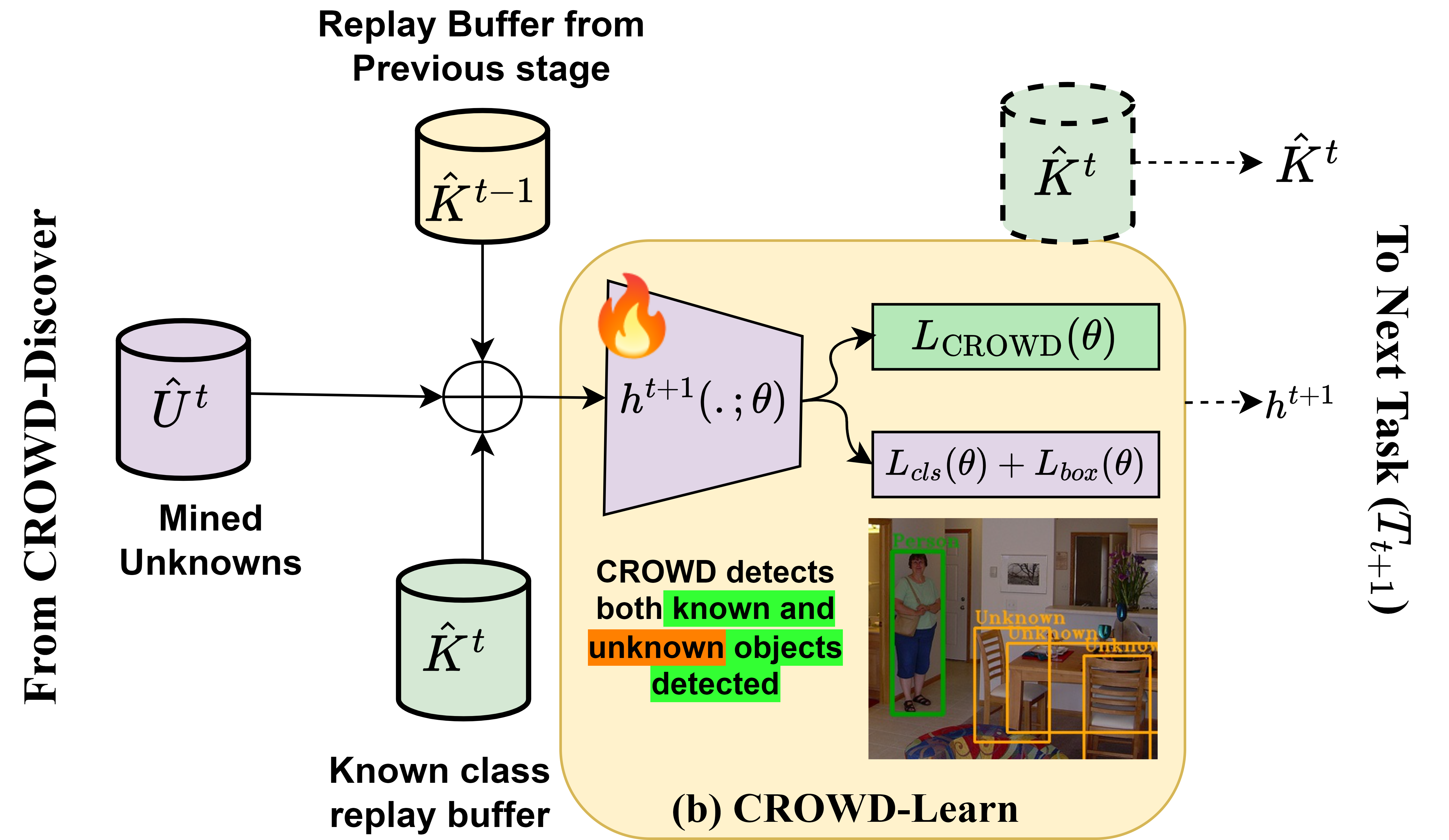
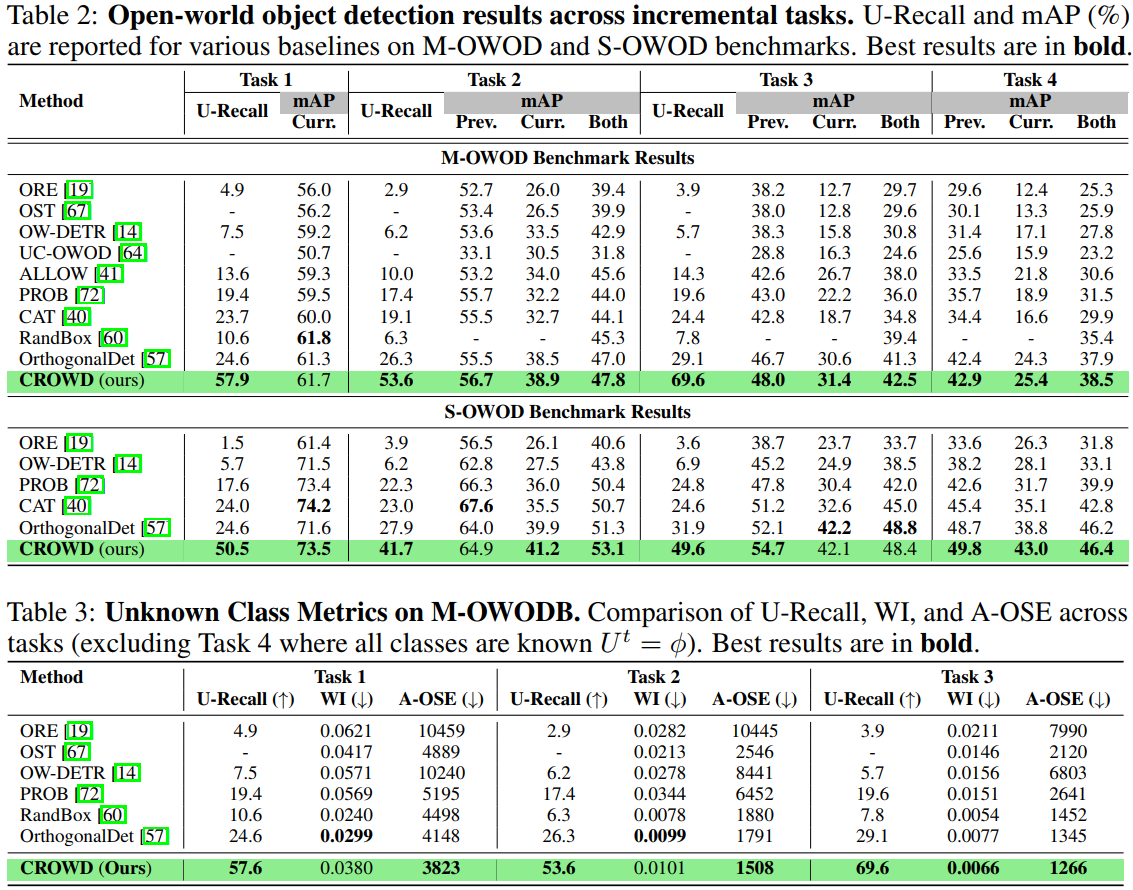
Overall Architecture of CROWD showing our novel combinatorial data-discovery guided representation learning approach to (a) identify unknown objects and (b) learn distinguishable representations of both known and unknown objects.
Abstract
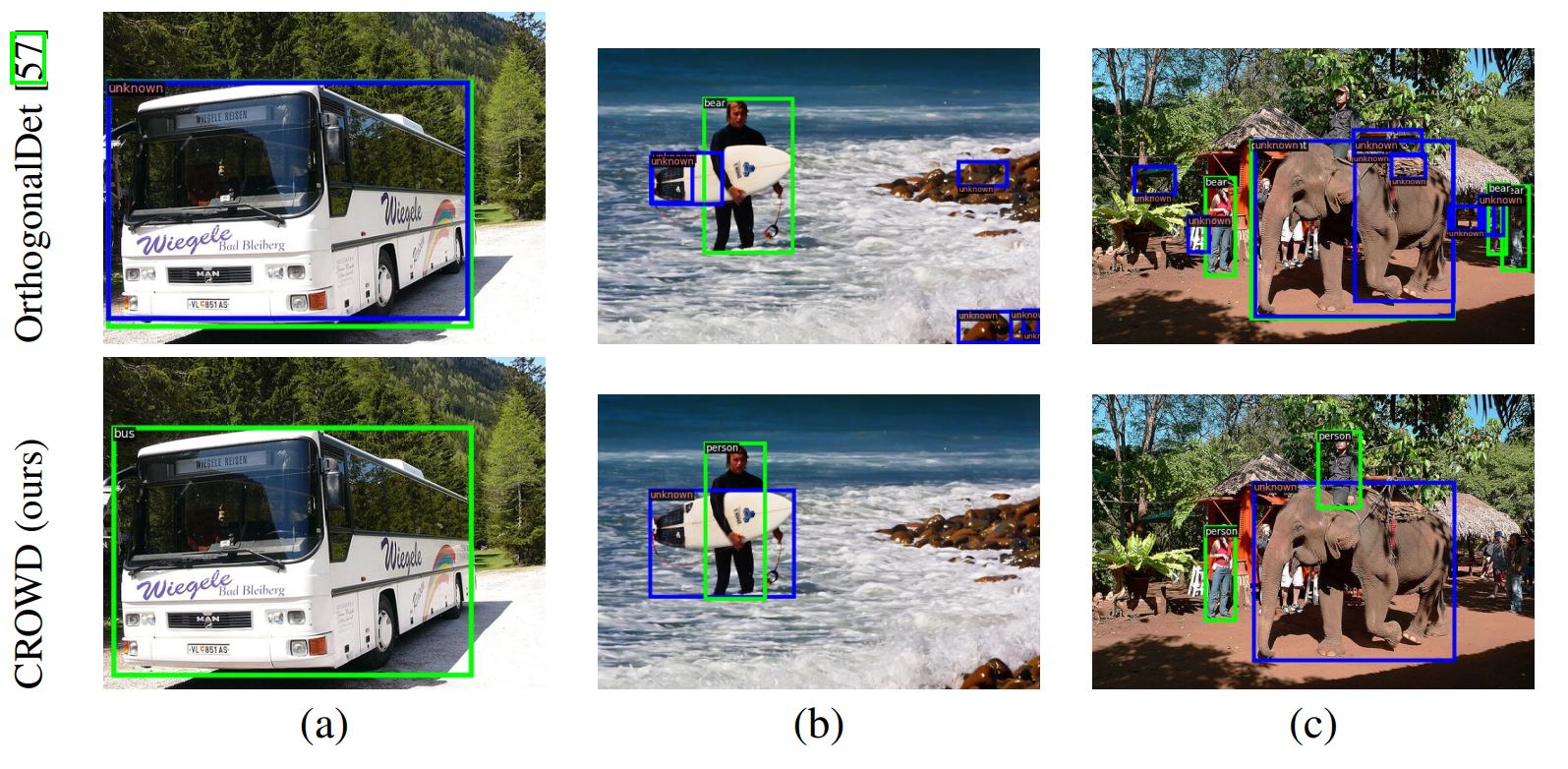
Open-World Object Detection (OWOD) enriches traditional object detectors by enabling continual discovery and integration of unknown objects via human guidance. However, existing OWOD approaches frequently suffer from semantic confusion between known and unknown classes, alongside catastrophic forgetting, leading to diminished unknown recall and degraded known-class accuracy. To overcome these challenges, we propose Combinator Open-World Detection (CROWD), a unified framework reformulating unknown object discovery and adaptation as an interwoven combinatorial (set-based) data-discovery (CROWD-Discover) and representation learning (CROWD-Learn) task. CROWD-Discover strategically mines unknown instances by maximizing Submodular Conditional Gain (SCG) functions, selecting representative examples distinctly dissimilar from known objects. Subsequently, CROWD-Learn employs novel combinatorial objectives that jointly disentangle known and unknown representations while maintaining discriminative coherence among known classes, thus mitigating confusion and forgetting. Extensive evaluations on OWOD benchmarks illustrate that CROWD achieves improvements of 2.83% and 2.05% in known-class accuracy on M-OWODB and S-OWODB, respectively, and nearly 2.4x unknown recall compared to leading baselines.
The CROWD Framework
CROWD casts Open-World Object Detection (OWOD) as a set-based discovery and learning problem. For each task \(t\),
we view the known object classes as a collection of sets \(K^t\) and aim at grouping all candidate unknowns
into a single pseudo-labeled set \(U^t\) while treating everything else as background \(B^t\).
This viewpoint surfaces two unique challenges in the domain of OWOD -
- How to identify instances of unlabeled unknown objects \(U^t\) given labeled examples of only known ones in \(K^t\) ?
- How to effectively learn representations of currently known objects without forgetting the previously known
(classes introduced in \(T_i\), where \(i < t\)) ones ?